|
Graphing and the Visual
Presentation of Data Part 1: Introduction and Basics
Introduction If math is a universal language, then graphs are the pictures we use to tell stories. Most of us are introduced to the coordinate axes and graphing in an elementary school science class, where a cursory description was provided. The next notable encounter is often geometry (then pre-calculus), where the data are all neat series, and style is of no importance and never considered. All to often, students must fend for themselves, based on occasional feedback on random lab reports, with no critical instruction on how to present visual analyses of data. I was lucky to have a fair amount of instruction early on: my 5th grade science teacher, Mr. Stokinger, and my 11th grade Calculus teacher Mrs. Wendy Newberry. Teaching Engineering Design Lab 5 for nearly 4 years now, I see that many college students have been given little guidance. Much of the"instruction" they do receive has been from those who wrote Microft Excel. It is evident that most (if not all) of my students have never even drawn a serious graph by hand. With some instruction in my classes and this page, I hope to make a significant impact on their data presentation skills.
Purpose and Goals After teaching the Design Lab V class for a few semesters, I began to see a lot of repeat mistakes in the way data was taken, manipulated, and represented. In order to combat the last aspect as thoroughly as possible, I began using the first (introductory) lab class to review the fundamentals of what amounts ot graphing and presenting data. This was incorporated class-wide the next semester, and after teaching the "Materials Lab" for 9 terms (yes, nine), this document has evolved to what you see before you. The purpose is not just for you to avoid having points taken off--unfortunately that is the only driving force in many cases--but to provide you with the basics denied you in grade school and high school. It is possible you were not denied the fundamentals, but you have forgotten them or become lazy (Excel will contribute to that). There is a certain point where changes become very subjective...but many if not all of the guidelines and details delineated herein will bring you up to that point. Most of this guidance is standard from any engineering perspective, much of it inspired by professional sources and repositories (such as journals), and some details "just makes sense". After subjecting your work to these guidelines, you can haggle over sans/-serif fonts, single and multi-line titles, and data series scheming. Do not let Excel do the thinking for you! Who says that whatever programmer(s)
who wrote various modules and functions knew how best to present or manipulate
your data? (Or, for that matter, any data set!) There are many reasons
to go the "extra mile" when putting even the most rudimentary
graph together: This document goes into what I beieve is a suffucient amount of detail to completely and accurately describe concepts and practices to most levels of readers. The tone is on the conversational side of prose, but I hope you will not hold this against it. Where felt helpful, reference graphs have been included to depict concepts and practices. The pictures included for reference are small, and to see the details, all one needs to do is click on a picture to see the full-size version. Further, almost nearly all graphs (and their respective data sets) are available in this Excel file for closer inpspection.
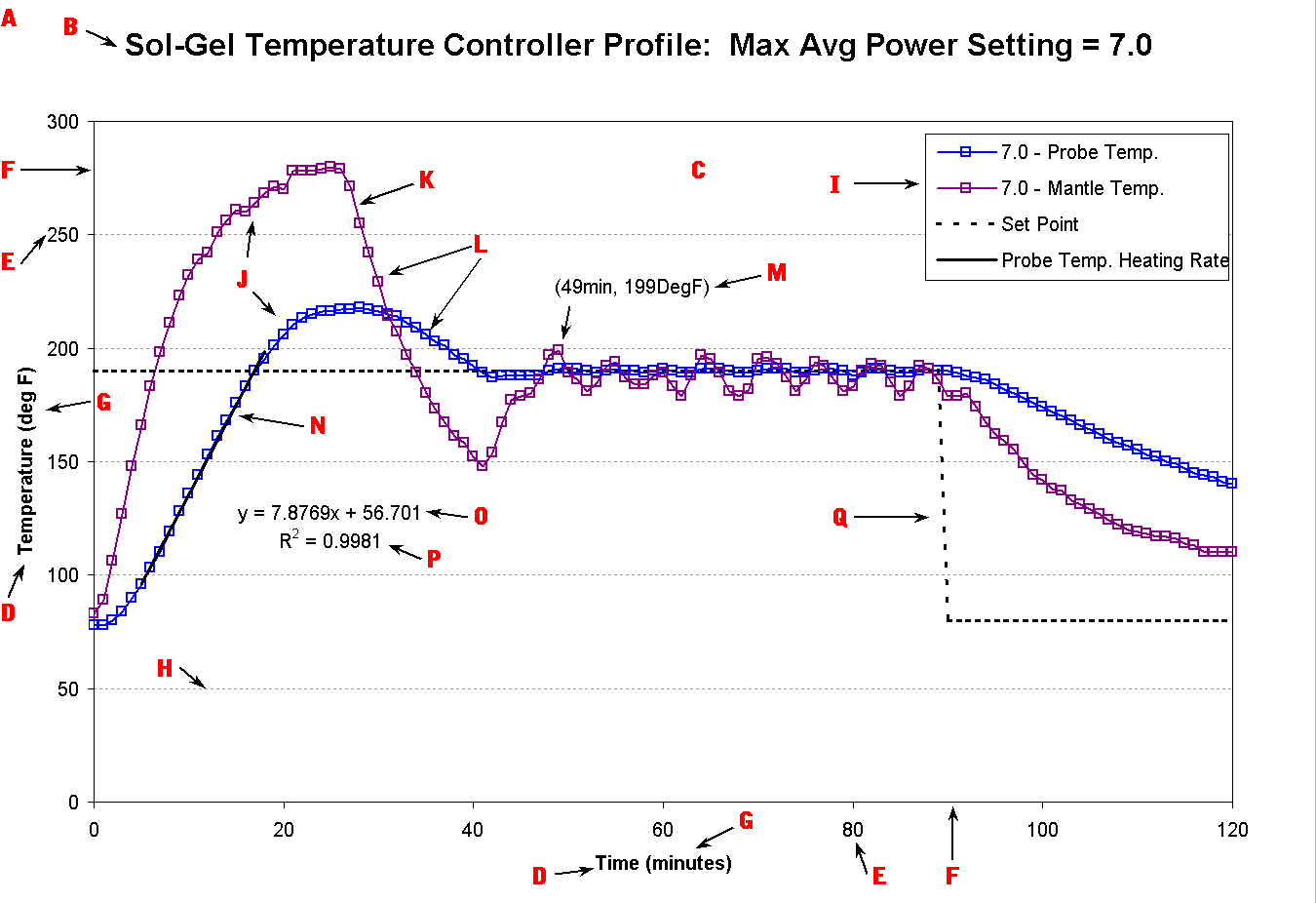
Definitions Just to get us started on the right foot, review the simple graph below
and confirm you are familiar with the terminology. There may be a few
terms which you may have seen used differently, but from my experience,
these are the most typical--and more importantly, accurate--definitions.
Axis ( F ): Axis Label ( D ): Axis Scale Numbers ( E ): Baseline ( Q ): Data Point ( L, M ): Graph ( A ): Grid Lines ( H ): Label ( M ): Legend ( I ): Marker ( L ): Plot ( J ): Plot Area ( C ): Plot Line ( K ): Significant Digits (not applicable): Series (used to create J): Title ( B ): Trend Line ( N ): Trend Line Equation ( O ): Trend Line Fit Value ( P ): Units ( G ):
Acquisition The measurement of good data involves much planning: epxperiment setup, parameters, signal measurement, signal processing, analysis, et cetera. Most of this, although important and interesting, is beyond the scope of this document. However, a few basic considerations will go a long way to ensuring your data is accurate and complete. Power is the first and most basic consideration. If necessary, measured devices should use "clean" power, not power right off the grid (out of the wall). Bench-top setups should keep power lines seperate from signal/measurement lines and shield the signal lines. Lines parallell to each other will have interfering magnetic fields, hence where possible, all wires should be seperate of cross at 90 degrees. The proper equipment should be used for measurement. Necessity is the mother of invention, but there is usually a right tool for each job...don't strecth equipment too far past its specifications and intended uses. When planning the experiment, estimate (or model) the output. Looking at what you expect or want will help plan the parameters. Of course, you should also have a question that is being answered...a distinct purpose for the work being done. Do not lose your objectivity, however. Use your expectation(s) for planning the experiment, not for analyzing the data. Planning should also give you some insight into the range of the data expected. Especially in the case of trends, the range over which observations are made and information is tracked. In the case of cyclic data, the definition of a "long" time will vary: 100 seconds for acoustics, 10 months for sleep patterns, 10 years for seasons, 10 decades for sunspots. It's all relative. When you measure (or inadvertently encounter) cyclic data, ensure you take enough data to show the trend, even if it is already known. For example, if you wanted to show seasonal passenger traffic on the subways lines of a subway system, data would obviously be collected for 12 months. In addition, two months or so of data collected on either end would demonstrate to the viewer that the extreme ends of the year really do correlate and the overlapping "tails" would demonstrate consistency. Lastly, remember that while a trend may be expected at one level, there may be another trend smaller or larger than the primary trend. Alter the perspective and make sure you are not showing just the macroscopic or microscopic picture.
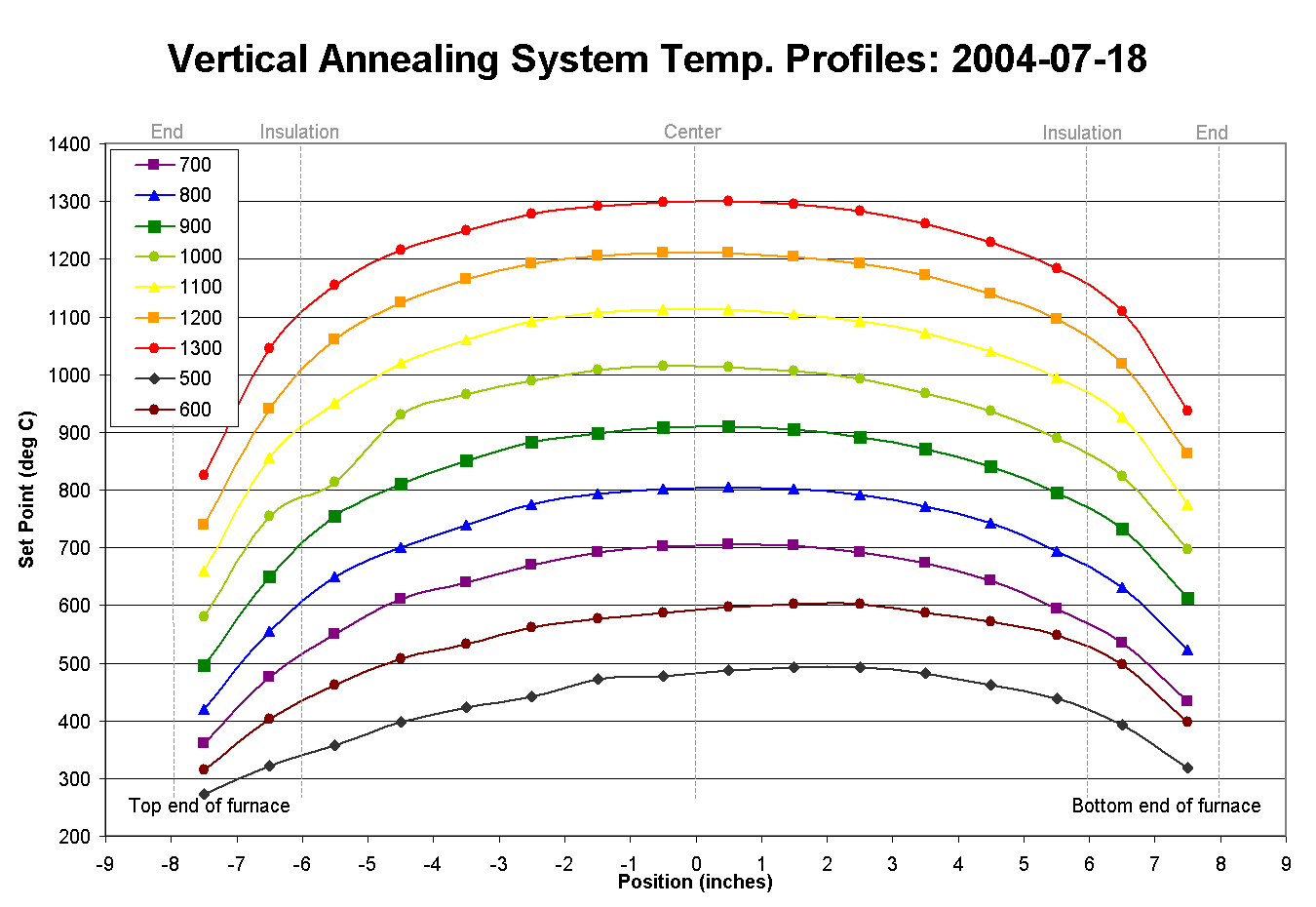
Data It may seem more appropriate to discuss data after acquisition, but in order to proplerly conduct an experiment--of which taking data is an integral part--proper planning is critical. Although, it may not be not that critical for putting together a really good graph. :-) On of the most common issues with data is significant digits. We will not go into this here, but extra digits after the decimal point indicate accuracy which is not there in data, and not necessary for axis scales (becuase it is imposed, not measured on an axis). How the data points are connected is also important. If 50 points were taken in 20 experiments, they should not be connected in one long series. But seldom should a graph have 20 series on it. Instead, a trend line(s) should be used. If a series of data typically fluctuates rapidly from point to point, as in a stock price, it should be connected with straight lines. (Observe the Net Revenues for Pipe Fittings, Inc graph below.) If a series typically moves gradually from point to point, as in a temperature profile, a smoothed curve should probably be used to connect the points. (See the Vertical Annealing System Temp. Profiles graph below.) If the data is not contiguous, however, DO NOT ever connect the dis-continuous points or series, this is too misleading to the viewer.
While on the subject of trend lines, many times a set of data will demonstrate a trend of some sort--linear, assymptotic, x^n, polynomial, et cetera. When this is the case, it is often a very good idea to model the data to see just how good the fit is. If it is not expected, the trend line can be a light gray, on a backup slide, or just the equation and fit value can be placed somewhere unobtrusive. When a trend is expected, it is good form (especially in a lab class) to fit the data with the expected trend and examine how good the fit is or is not. If a completely different trend is observed--from what is expected--first analize you data manipulation and graph to ensure no mistakes have been made before you continue with the error analysis of your experiment. Trend lines are sometimes used to prognosticate beyond the data set. [As an aside, this is technically referred to as "extrapolation". Extrapolation, however, is generally done for "future" data within some percentage distance of the main data range (up to 30% prior to or beyond the current range, for example). Prognostication in this sense refers to estimating trends beyond 30% of the current data range.] When data is used to prognosticate, it must be made very clear, both with a text label of some kind (i.e. "Expected 4th Quarter Earnings") and with a viusual cue (color change or bright drawing element). Lastly, be very careful with the use of drawing elements, point labels,
trend lines, markers, et cetera. They should not obscure the data or plot
line, be too thick or faintly-colored, or create visual congestion or
confusion for the viewer.
Significant Digits The issue of inappropriate significant digits seems to come up when students digitize their data and perform some manipulation, such as graphing or a calculation. Basically, significant digits are those which indicate value, not just hold a place. For example, if a machine measures force in 1000's of pounds, a typical result might be 23,500 pounds (many measurements recognize the accuracy of 1/2 of a gradation, but not all). In this case the 2 and the 3 are significant digits, the 5 is arguable, and the two 0s are place holders, not significant. As such, the following are numbers which mis-represent the accuracy of the machine: 23,500 lbs; 23,500.0 lbs; 23.500*10^3 lbs; and 23.4E3 lbs (trying to refine the reading from a dial or scale by estimating the reading is just below 500 lbs). In the strictest sense, all of the zeros to the right of the numbers are implying accuracy which is not there. The ideal way to record the number is using scientific notation: 23.5*10^3 lbs or 23.5E3 lbs. On the other side of the number, however, extra zeros can only be used as place holders and do not imply accuracy which is not actually present (i.e., 0.005 inches). When performing calculations, most spreadsheet programs do not "autoformat" the resulting answer/cell to the proper number of significant digits. This is where one must look at the originating data, find the specie with the lowest number of significant digits, and propagate that to the calculation's cells. This also ensures data will be readable to others.
Accuracy versus Resolution These two concepts are related in subtle and important ways. Resolution is the ability to see and/or measure the difference between two levels of intensity--be they height, heat, or light. This is acheived by measuring the levels of some signal with an appropriate size step--the smaller the step size, the smaller the difference which may be measured. Accuracy is the size of the step you can measure...be it 1 or 2 mm, 0.01 or 0.05 mm or 1 or 5 microns (1*10E-6 meters). As such, the increased accuracy of our instrumentation permits measurement with a greater degree of resolution. Resolution also has another facet which comes into play when creating a graph. The resolution apparent to the viewer depends on the scaling of either axis, although it is usually more noticeable on the y-axis. Let us suppose a series measuring the height of plants in a field fluctuates between 1 and 20 inches. If an old tree were in the sample set measured, it would be several hundred inches tall--1 to 2 orders of magnitude taller than anything else. Accomodating this "outlier" on the graph would reduce the relative size of all the other data in the series, making distinction much more difficult. [This effect is also described at reducing the "line definition".] So, while the accuracy of the data's measurements is there, it is not really observable to the viewer: little could be observed about the bulk of the data other than it is much smaller than the one outlier. Assuming the outliers are few and of minimal importance, the best way to graph the data would be to scale the y-axis to fit the main body of data and label the outliers with data labels, allowing them to extend off the plot area. Remember that accuracy is part of the instrumentation, but can be severly impeded by the user if care is not taken in setup, usage, and care of the equipment.
|
| Copyright (c) 2005 by Justin Daniel Meyer. Material on this page subject to this reproduction agreement. |